Note
Hôm qua mình có đi interview và không ổn lắm. Nhưng khi về thì có một vài câu hỏi làm mình suy nghĩ khá nhiều (mình không nhỏ nhen đâu nhé 😚). À, chúc mọi người 30/4 vui vẻ 🇻🇳, nay 29/4 rồi.
1. Hãy implement queue với size bất kỳ
Interviewer muốn tìm một cách nào đó để implement queue thỏa 2 điều kiện: có thể handle bất kỳ size nào và tối ưu.
a. Linked List
Đúng như đề bài trên, mình sẽ phải tìm cách implement một queue sao cho tối ưu nhất có thể, giờ ta xem queue sẽ gồm những gì nhé:
- Một hàm
enqueuedùng để thêm một phần tử bất kỳ vào cuối queue. - Một hàm
dequeuedùng để lấy phần tử đầu tiên ra khỏi queue (dựa theo nguyên tắc FIFO).
Một cách mà các bạn thường thấy trong khi học DSA (và cũng là cách mà interviewee mong muốn làm) đó chính là dùng Linked List với head và tail, việc dùng tail sẽ tránh đi việc di chuyển từ đầu Linked List đến cuối Linked List để thực hiện hàm enqueue, vậy là “theo lý thuyết” từ ta đã giảm còn độ phức tạp. Còn đối với hàm dequeue ta chỉ cần thay đổi head là được thê nên “theo lý thuyết” nó cũng là , phía dưới là code của Linked List cho queue.
struct Node { Node *next = nullptr; int data = 0;};
struct QueueLinkedList { Node *head = nullptr; Node *tail = nullptr; int size = 0;
~QueueLinkedList() { while (head != nullptr) { Node *tmp = head; head = head->next; delete tmp; } tail = nullptr; // head is already nullptr }
int dequeue() { assert(!is_empty()); Node *temp = head; int data = temp->data; head = head->next; if (head == nullptr) { tail = nullptr; } delete temp; return data; }
void enqueue(int value) { Node *new_node = new Node; new_node->data = value; if (is_empty()) { head = new_node; tail = head; size = 1; return; } tail->next = new_node; tail = new_node; size += 1; }
bool is_empty() { return head == nullptr; }
int front() { assert(!is_empty()); return head->data; }};b. Array
Bây giờ ta sẽ qua một cách implement khác là sử dụng Circular Buffer 1 hay còn gọi là Ring Buffer 2 (một cách implement “tối ưu” hơn rất nhiều nhưng về mặt độ phức tạp thì không).
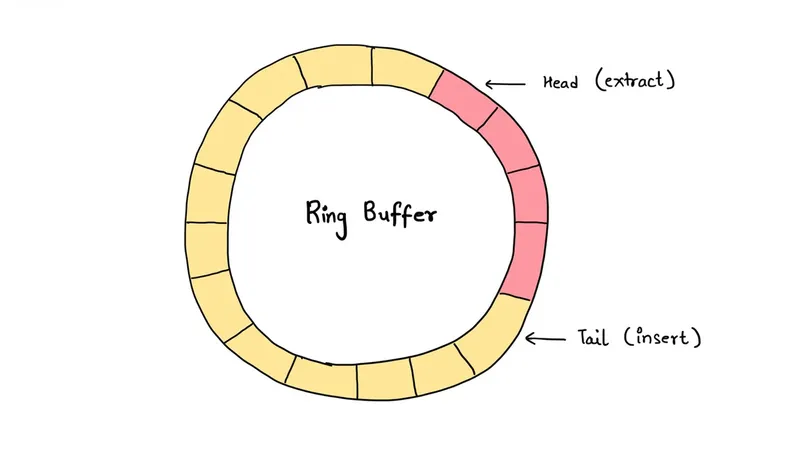
Ok, một circular buffer thật là một array nhưng thay vì chỉ thêm các phần tử vào bên phải array và xóa đi phần tử bên trái cùng (gọi là head hoặc front) của array thì ta vẫn làm tương tự, thế nhưng nếu phần tử bên phải cùng (gọi là rear hoặc tail) không thể thêm được nữa, ta sẽ wrap-around (xoay ngược lại) và thêm vào đầu array (như một hình trong do đó có tên circular).

Giờ qua phần implement thôi nào (các bạn có thể về nhà xem kĩ hơn 👍) (code dưới mình nhờ AI generate ra cho nhanh, xin lỗi vì sự bất tiện này 💀).
struct QueueArray { int *arr = nullptr; int head = 0; int tail = 0; int size = 0; int capacity = 0;
~QueueArray() { std::free(arr); }
int dequeue() { assert(arr != nullptr && size != 0); int result = arr[head]; head = (head + 1) % capacity; size -= 1; return result; }
void enqueue(int value) { if (arr == nullptr) { assert(size == 0 && head == 0 && tail == 0); capacity = 10; arr = static_cast<int *>(std::malloc(capacity * sizeof(int))); arr[tail] = value; tail = (tail + 1) % capacity; size = 1; return; }
if (size == capacity) { int old_capacity = capacity; capacity *= 2; int *new_arr = static_cast<int *>(std::malloc(capacity * sizeof(int)));
for (int i = 0; i < size; ++i) { new_arr[i] = arr[(head + i) % old_capacity]; }
std::free(arr); arr = new_arr; head = 0; tail = size; }
arr[tail] = value; tail = (tail + 1) % capacity; size += 1; }
int front() { assert(size > 0); return arr[head]; }};Có thể thấy (tính nhẩm một tí) cả 2 operation là enqueue và dequeue của Circular Buffer đều là , lưu ý là trường hợp size và capacity bằng nhau (phải tạo mới) thì lúc này enqueue là do phải copy phần tử từ array cũ sang array mới. Thế nhưng rất ít xảy ra nên có thể giả sử rằng time complexity trung bình của operation enqueue Circular Buffer là . Vậy cả hai Linked List và Circular Buffer đều có time-complexity là như nhau.
Giờ chạy thử benchmark trên 1 tỷ phần tử để thử xem cái nào tốt hơn, phía dưới là Benchmark Code:
constexpr int BENCHMARK_LOOP = 1'000'000'000;volatile long long array_dequeue_sum = 0; // Use volatile to prevent optimizationvolatile long long ll_dequeue_sum = 0;
#define BENCHMARK(func, name) \ [&]() { \ auto t1 = high_resolution_clock::now(); \ func(); \ auto t2 = high_resolution_clock::now(); \ duration<double, std::milli> ms_double = t2 - t1; \ std::cout << name << " run for " << ms_double.count() << "ms\n"; \ }();
int main(int argc, const char *argv[]) { using std::chrono::duration; using std::chrono::high_resolution_clock;
QueueArray q_arr; QueueLinkedList q_ll;
BENCHMARK( [&q_arr]() { for (int i = 0; i < BENCHMARK_LOOP; i++) { q_arr.enqueue(i); } }, "QueueArray::Enqueue")
BENCHMARK( [&q_arr]() { for (int i = 0; i < BENCHMARK_LOOP; i++) { array_dequeue_sum += q_arr.dequeue(); } }, "QueueArray::Dequeue")
BENCHMARK( [&q_ll]() { for (int i = 0; i < BENCHMARK_LOOP; i++) { q_ll.enqueue(i); } }, "QueueLinkedList::Enqueue")
BENCHMARK( [&q_ll]() { for (int i = 0; i < BENCHMARK_LOOP; i++) { ll_dequeue_sum += q_ll.dequeue(); } }, "QueueLinkedList::Dequeue")
return 0;}Phía dưới là kết quả benchmark (chạy trên Macbook M2 của mình và không sử dụng bất kỳ compiler optimization nào), có thể thấy thời gian enqueue của một tỷ phần tử của LinkedList gấp gần 6 lần 💀 so với Circular Buffer, ngoài ra không chỉ thời gian enqueue và thời gian dequeue cũng gấp hơn 3 lần. Performance càng cách xa khi càng nhiều phần tử, điều này là do có một chỗ nào đó bị bottleneck.
# 10 triệu phần tửQueueArray::Enqueue run for 134.672msQueueArray::Dequeue run for 92.7956msQueueLinkedList::Enqueue run for 190.325msQueueLinkedList::Dequeue run for 215.375ms# 100 triệu phần tửQueueArray::Enqueue run for 1457.19msQueueArray::Dequeue run for 957.006msQueueLinkedList::Enqueue run for 2146.44msQueueLinkedList::Dequeue run for 2130.74ms# 1 tỷ phần tửQueueArray::Enqueue run for 14533.7msQueueArray::Dequeue run for 9838.72msQueueLinkedList::Enqueue run for 78361.1msQueueLinkedList::Dequeue run for 30657msĐiều này là do đâu ? Time complexity đều bằng nhau mà ! Đây chính là lý do mà mình khá “không thích” việc mọi người tập trung “tối ưu” thuật toán mà bỏ qua các mặt khác của ngôn ngữ đang code hoặc hardware, một câu mà mình luôn nói với mình (đồng thời bao biện cho việc mình ngu thuật toán) chính là mình làm việc với máy tính, mình không làm việc trên giấy.

Dựa vào ảnh trên, có thể thấy phần code nặng nhất nằm ở QueueLinkedList::enqueue khi mà nó chiếm đến thời gian code chạy. Vậy chính là, việc new hay allocate bộ nhớ liên tục làm bottleneck code, làm cho code chạy chậm đi rất nhiều, trong khi đó, cùng với một time complexity QueueArray::enqueue chỉ chiếm thời gian code chạy. Tương tự như enqueue, dequeue của QueueLinkedList cực kì tốn kém khi chiếm (tất cả là do việc new và delete liên tục đấy). Vì vậy (đối với riêng ngôn ngữ C/C++ thôi nhá), việc xem xét đến những khía cạnh của ngôn ngữ, bộ nhớ cực kì quan trọng nếu muốn viết code thật sự tối ưu.
Các bạn có hỏi tại sao lại chọn array chưa, đó chính là tránh đi dynamic allocation 3 (như các bạn thấy ở trên đây là một hàm cực kỳ expensive và kéo performance của Linked List xuống tận đáy). Để tránh đi dynamic allocation ta sẽ thử chọn array và đi qua nhiều bước để tối ưu nó.
struct Queue { float* arr; size_t size;
~Queue() { delete[] arr; }}Thế nhưng một điều ta thấy là array có một size cố định (gọi là ) vì vậy nếu ta muốn thêm phần tử mới (ở operation enqueue) thì khi đó ta phải tạo một array mới có size là và copy toàn bộ phần tử từ array cũ sang array mới và nó chả giúp ích gì khi mà việc tạo array mới chính là dynamic allocation.
void Queue::enqueue(float value) { // tạo array mới với size N + 1 float* tmp = new float[size + 1]{}; // copy array cũ sang std::memcpy(arr, tmp, size); tmp[size] = value; // xóa array cũ và gán giá trị mới delete[] arr; arr = tmp; size += 1;
// siêu tốn kém khi mỗi lần enqueue lại là một lần dynamic allocation // không khác gì linked list và còn phức tạp hơn}Vậy để tránh nhiều lần dynamic allocation, ta có thêm một biến là capacity, thay vì allocate đúng phần tử, ta allocate capaciy phần tử, vì vậy sẽ tránh được nhiều lần allocate.
void QueueCapacity::enqueue(float value) { if (size + 1 > capacity) { // tạo mới array nếu vượt quá capacity capacity *= 2; // capacity mới gấp đôi cũ float* tmp = new float[capacity]{}; // tương tự phía trên // std::memcpy ... return; } size += 1 arr[size] = value;}Thế nhưng nếu implement bằng array thì một cách để dequeue (hay xóa đi phần tử đầu) đơn giản là bỏ phần tử đó đi, ta vẫn giữ được time complexity là . Thế nhưng sẽ tạo ra một “khoảng trống” phía trước của array (có thể thấy ở hình 2). Do đó ta đến với cấu trúc tối ưu nhất là Circular Buffer đã được nói ở phía trên.
2. For loop chạy bao nhiêu lần ?
Cho bài toán sau 4 , for loop được chạy bao nhiêu lần ?
unsigned char half_limit = 150;
for (unsigned char i = 0; i < 2 * half_limit; ++i){ // do something;}Có thể thấy unsigned char là một kiểu dữ liệu có độ dài là 1 byte, do đó giá trị tối đa mà i có thể có là . Trong khi đó 2 * half_limit là . Hmm, bắt đầu thấy khó. Theo logic thông thường, số cần đến 9 bit để biểu diễn thế nhưng unsigned char chỉ có 1 byte = 8 bit. Vì vậy việc xảy ra đó chính là wrap-around 5 vậy giá trị 2 * half_limit nên là 300 % 256 = 44. Do đó for-loop sẽ chạy lần, đúng không ? Không.
Việc này là do mình đang có 2 assumption:
- C/C++ sẽ đảm nhận công việc wrap-around khi mà số bị overflow.
- C/C++ thực sự nhân
2vớihalf_limitvới nhau ở kiểu dữ liệu làunsigned char.
Thật ra trường hợp này sẽ gây ra cái gọi là undefined behavior, nó sẽ khác nhau tùy thuộc vào compiler, môi trường, … có thể compiler A sẽ wrap-around, compiler B không làm như thế. Còn assumption thứ 2, trong C/C++ sẽ có một thuật ngữ gọi là type-promoting, sẽ có những type “cao” hơn những type khác (dựa vào số bit cần biểu diễn type đó), ở đây 2 là int (4 bytes = 32 bits) và half_limit là unsigned char (1 bytes = 8 bits) vì vậy C++ sẽ đưa half_limit lên type cao hơn (là int) khi đó, vòng for loop có thể viết lại như sau:
unsigned char i = 0;while ((int)i < 2 * (int)half_limit) { // do something ++i;}Do đó khi mà i có giá trị là 255 và ++i (vượt quá 255) thì sẽ dẫn đến wrap-around vậy i = 255 % 256 = 0, lúc này vòng lặp sẽ lặp vô hạn 6 .
3. Modern C++
Mình khá buồn vì interviewer không hỏi về cái này nên mình sẽ dành chút thời gian để giới thiệu về nó 😚
a. Smart pointer
Ở C/C++, chúng ta có 2 loại bộ nhớ là Heap và Stack, khi tạo một biến như dưới đây:
int a = 3;Thì a sẽ được C tạo trên stack, vùng nhớ này đúng như cái tên nó như 1 stack, có thứ tự và C sẽ đảm nhận việc xoá các biến trên stack nếu không cần tới nữa hoặc ra khỏi scope của nó, à một concept nữa là scope, scope trong C/C++ được biểu thị bằng dấu {}, ví dụ như dưới đây:
// các biến ở ngoài đây có scope global
void func() { // các biến ở đây có scope là hàm func}
int main(void) { // các biến ở đây có scope là hàm main // ta có thể làm như này luôn { // các biến ở đây chỉ có scope trong ngoặc này } // sau khi hết scope (ra khỏi dấu }) // các biến sẽ được xoá đi}// tương tự hết scope hàm mainCòn khi tạo một biến trên heap, bằng new (C++) hay malloc (C), thì biến đó sẽ được nằm ngẫu nhiên trên bộ nhớ, không có thứ tự như Stack, ngoài ra C/C++ cũng không đảm nhận việc xoá các biến này đi nếu nó ra khỏi scope. Và điều đặc biệt hơn, pointer là một biến nằm trên stack nhưng biến mà pointer đang trỏ đến nằm trên heap, do đó sẽ xảy ra trường hợp pointer bị out of scope, dẫn đến pointer bị xoá nhưng biến mà pointer trỏ đến trên heap vẫn chưa bị xoá (không ổn đâu), vì vậy ta phải luôn để ý khi nào cần xoá biến mà pointer đang trỏ đến, và để xoá sẽ dùng delete (C++) hoặc free (C).
Thấy vấn đề đó, smart pointer ra đời ở C++ (bản 11 trở lên), bao gồm 2 loại smart pointer là unique_ptr (unique pointer) và shared_ptr (shared pointer). Nếu để ý cái tên của nó, mỗi smart pointer sẽ có owner (người sẽ đảm nhận việc xoá đi biến mà pointer đang trỏ đến hay còn gọi là resource, gọi là người cũng không đúng, thật ra là compiler xoá ấy). Ở unique_ptr, chỉ có duy nhất một owner đảm nhận việc này, còn shared_ptr thì sẽ có nhiều người cùng nhận việc này. Khi các owner bị huỷ (hoặc out of scope) thì nó cũng tự xoá đi resource mà nó đang trỏ đến.
Ở unique_ptr, để đảm bảo tính duy nhất, phép gán bằng = và copy constructor đều không thể dùng được, ta phải dùng đến cái gọi là move constructor (cái này sẽ là một concept mới của C++), bạn có thể hiểu là nó move cái ownership từ biến này sang biến khác. Còn shared_ptr thì gán bằng = hay copy thoải mái và đặc biệt, khi các shared_ptr bị xoá (hoặc out of scope), C++ sẽ xem đến khi nào thằng shared_ptr cuối cùng bị xoá thì nó mới bắt đầu xoá luôn resource.
// tạo pointer a trỏ đến biến int = 3std::unique_ptr<int> a = make_unique<int>(3);std::shared_ptr<int> b = make_shared<int>(4);// còn lại tương tự pointer// ta có thể deferencingstd::cout << *a; // 3std::cout << *b; // 4b. Move Semantics
Ở phía trên mình đã nhắc đến std::move vậy bây giờ ta cùng tìm hiểu xem move semantics của C++ là gì nhé ?
🚧 Hope mình có thêm thời gian để viết cái nì
c. Template
🚧 Hope mình có thêm thời gian để viết cái nì
Footnotes
-
https://www.damianopetrungaro.com/posts/data-structure-circular-buffer/ ↩
-
Dynamic Allocation sẽ chỉ đến nhưng lần mà ta dùng
newhaymalloc, lúc này một resource mới được tạo trên heap memory. Xem thêm ở https://www.reddit.com/r/embedded/comments/u31pse/why_is_dynamic_memory_allocation_bad/ ↩ -
https://stackoverflow.com/questions/60364379/overflow-of-an-unsigned-char-in-c ↩
-
Theo C++ các kiểu unsigned sẽ được wrap-around, còn các kiểu signed sẽ tùy compiler, do đó dẫn đến undefined behavior. ↩