Nếu các bạn chưa đọc phần 1 thì hãy đọc qua nó nhé (đọc sơ thôi cũng được), phần 1 ở đây
1. Transformers (Optimus biến hình)
Cuối cùng, ta sẽ đến ý tưởng thay đổi hoàn toàn AI nói chung và ngành NLP nói riêng (thay đổi cả thế giới luôn, kể cả mình), đó chính là kiến trúc Transformers
Ngoài ra, việc loại bỏ RNN giải quyết được hai vấn đề lớn:
- Tốc độ training: RNN phải xử lý tuần tự, không thể song song hóa. Mô hình chỉ dựa trên Attention có thể xử lý tất cả các từ trong câu cùng một lúc, nhanh hơn rất nhiều.
- Vanishing Gradients: Vấn đề “trí nhớ ngắn hạn” của RNN trên các chuỗi dài được giải quyết hoàn toàn.
2. Self-Attention: Một câu tự “nhìn lại” chính mình
Thay vì Attention giữa Decoder và Encoder, Self-Attention cho phép các từ trong cùng một câu tương tác với nhau. Để hiểu được nghĩa của từ “nó” trong câu “Con mèo nằm trên tấm thảm vì nó đã mệt”, cơ chế self-attention của từ “nó” sẽ học cách “chú ý” vào các từ trước và từ “mèo” sẽ được chú ý nhiều nhất (có score cao nhất). Đây là cách mà Transformers xây dựng biểu diễn (representation) cho mỗi từ trong câu (một ứng dụng gián tiếp của distributional hypothesis).
Một cách formal hơn, Self-attention sẽ lấy input là tương ứng với input token tại vị trí (hay bước thời gian ), một context gồm từ trước đó, tương ứng với và sinh ra output . Vì vậy với một câu gồm , đưa qua lớp self-attention, ta sẽ có các output là .
Tương tự như ở Encoder-Decoder, ở mức cơ bản nhất, giá trị attention chính là weighted sum của các context vector (các vector của từ trước đó) và quan trọng nhất đó là tính được weight :
Tiếp theo, làm sao để tính được weight , ta sẽ dùng hàm score gọi là , hàm này sẽ cho biết độ liên quan hay độ tương đồng giữa token hiện tại với các token trước , cách dễ nhất là dùng hàm dot-product làm score hay còn gọi là dot-product attention:
Việc tính attention bao gồm luôn tính cả score giữa cả token hiện tại và chính nó.
3. Attention Head
Ở transformer, ta sẽ gọi giá trị của Attention mechanism là head và gọi chung là attention head. Trước tiên, thay vì sử dụng thẳng input , input sẽ được “phân chia” thành 3 role là Query, Key và Value (tương tự, các từ trước đó hay context word cũng được chia thành 3 role).
Trong đó và là ba ma trận tham số tương ứng của 3 role là Query, Key và Value. Còn và là các vector embedding tương ứng với 3 role. Ngoài ra ta còn một ma trận dùng để đưa output của attention sang output cuối cùng là .
Thêm 3 gia vị Query, Key, Value vào self-attention đơn giản phía trên (tuy nhiên ta thấy dot-product giữa query và key có thể rất lớn do đó ta sẽ scale với factor là nghịch đảo căn của , với là chiều của vector key, do đó ta còn gọi là Scaled Dot Product Attention):
Important (Vai trò của Query, Key, và Value: Một ví dụ)
Để hiểu rõ vai trò của , hãy dùng một ví dụ như sau: bạn là một nhà nghiên cứu (token hiện tại) cần thu thập thông tin.
- Query (Q) - Câu hỏi bạn đặt ra:
Bạn có một chủ đề nghiên cứu cụ thể (ví dụ: “ảnh hưởng của AI đến kinh tế”). Bạn viết nó ra một tấm thẻ để đi tìm kiếm. Vector Query chính là “câu hỏi” mà token hiện tại đặt ra cho tất cả các token khác trong chuỗi. - Key (K) - Nhãn của thông tin:
Mỗi cuốn sách trong thư viện (mỗi token khác) đều có một cái nhãn (title) trên gáy sách tóm tắt nội dung của nó (ví dụ: “Lịch sử AI”, “Kinh tế học vĩ mô”). Vector Key của một token đóng vai trò như một “nhãn dán”, quảng cáo về loại thông tin mà nó chứa. - Value (V) - Nội dung thực sự:
Nội dung chi tiết bên trong mỗi cuốn sách chính là Value. Đây là thông tin thực chất, đầy đủ mà token đó có thể cung cấp.
Quá trình Attention:
- Tìm kiếm: Lấy Query (chủ đề cần nghiên cứu) và so sánh nó với từng Key (nhãn của mỗi cuốn sách) để xem cuốn nào liên quan nhất. Phép so sánh này (dot product) tạo ra attention score.
- Tổng hợp: Dựa trên điểm số, lấy một chút nội dung từ mỗi cuốn sách hay Value. Cuốn nào càng liên quan, ta càng lấy nhiều nội dung hơn. Output cuối cùng là tổng hợp có trọng số của tất cả các Value.
Chiều của input cùng chiều với output là và ta gọi là model dimension. Ta sẽ có chiều với query bằng nhau tức là và từ giờ ta sẽ sử dụng cho cả query với key, khi ấy và sẽ có chiều là . Còn sẽ có chiều là với là chiều của value. Vậy, chiều của attention-head sẽ là . Để có được chiều của output là , ta cần ma trận output có chiều là . Trong bài báo gốc
4. Multi-Head Attention, siêu sức mạnh của Transformers
Ở phía trên ta chỉ dùng single attention head thế nhưng trong Transformers Block thì ta sẽ dùng multi-head attention, tức là sẽ gồm nhiều attention head được đặt song song với nhau, mỗi attention head sẽ có bộ tham số của riêng mình.
Vậy attention head thứ sẽ có và . Ta sẽ cho input đi ta qua từng attention head để có được output và concat các attention head lại để có được output cuối cùng, sau đó đưa output đó sang ma trận output () để có được output cuối cùng.
Việc sử dụng nhiều attention-head mục đích là ta muốn chú ý (hay học) được nhiều relationship giữa từ hiện tại với context, ví dụ như các linguistic relationship hay semantic relationship, …
Trong bài báo gốc, số lượng head là .
Trong đó là vector query của input time tại head thứ , trong đó vector query sẽ có chiều là , tương tự với , còn cũng tương tự nhưng có chiều là . Trong đó input sẽ có chiều là với là model dimension. Ma trận sẽ có chiều là với là tổng số attention head và nghĩa là concat vector.
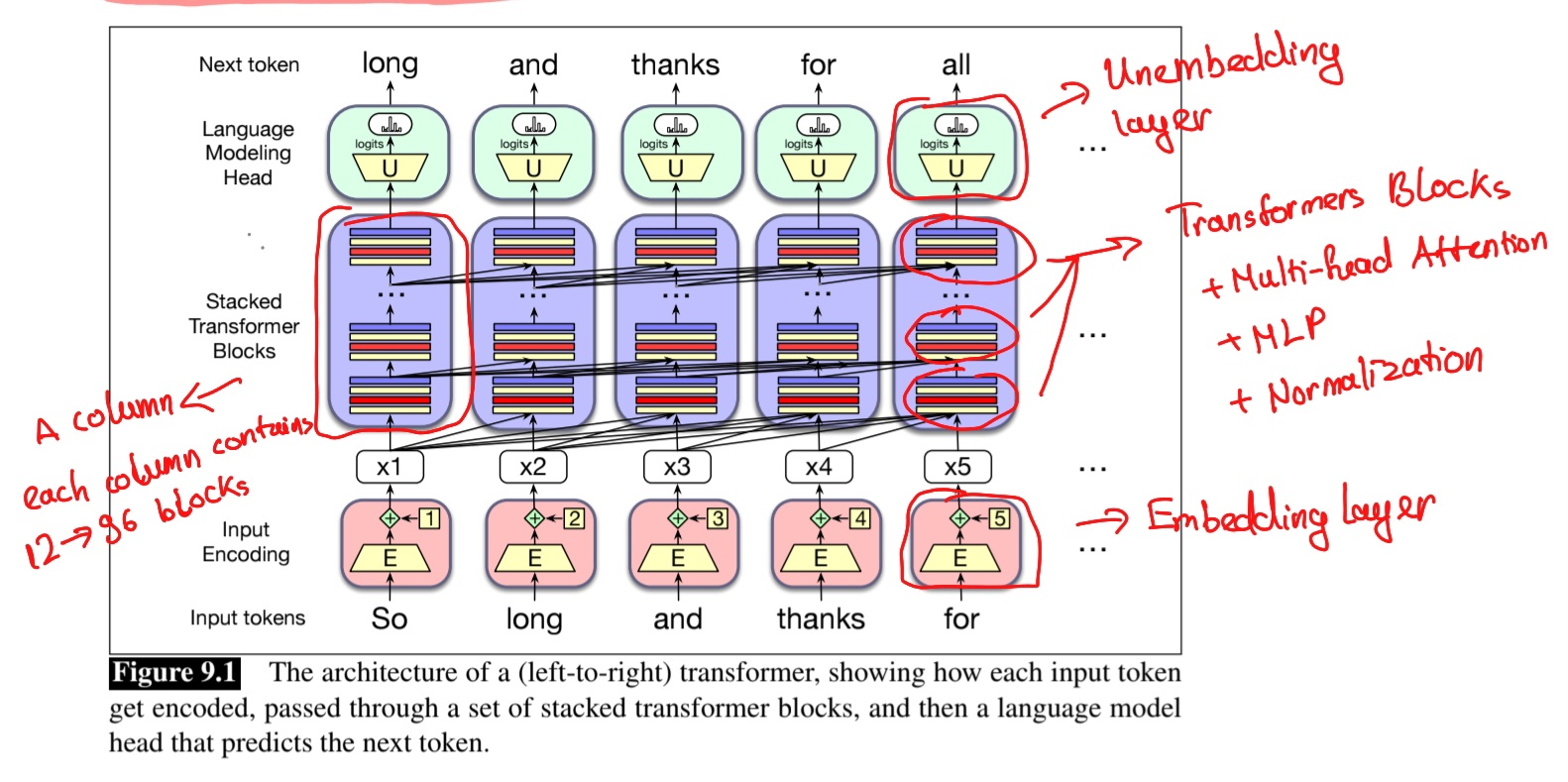
5. Transformers Block

Một Transformers Block đầy đủ sẽ bao gồm các component sau:
- Một MultiHead Attention, cũng có thể gọi là Attention Layer.
- Một Feedforward Layer (bao gồm một MLP), cũng còn được gọi là MLP Layer.
- Các Layer Normalization sau mỗi component phía trên (ở hình trên, ta dùng prenorm do đó layer norm nằm trước, thật ra trong bài báo gốc, họ dùng postnorm, tức là các layer norm nằm sau các component).
- Residual stream (dựa trên ý tưởng của residual connection của ResNet). Sau khi giá trị input qua mỗi component, nó sẽ được cộng lại với chính nó .
Residual Stream là một trong những concept quan trọng nhất của Mechanistic Interpretability và sẽ được nói đến rất nhiều ở phần 3.
Feedforward layer:
Là một mạng fully-connected 2 layer, activation là ReLU (hoặc là GeLU trong các mô hình mới hơn) và hidden dimension là (trong bài báo gốc ) và chiều của input là (model dimension).
Layer Norm:
- Tại mỗi component của Transformers Block, ta đều có LayerNorm (đứng trước hoặc sau, theo bài báo gốc là sau). LayerNorm sẽ normalize các giá trị của input dùng để improve training performance đồng thời giữ giá trị của hidden layer trong khoảng (tránh quá nhỏ hoặc quá to).
- LayerNorm là một variation của z-score và apply trên một single vector trong hidden layer (chứ không phải toàn bộ transformer block layer). Đầu tiên ta tính mean và của từng phần tử trong vector (xem vector như một phân phối), xét một vector input , ta có:
- Sau đó, vector normalize của vector gốc (chú ý, và là scalar, do đó ta sẽ trừ từng phần tử cho và chia từng phần tử cho ) sẽ là:
- Cuối cùng LayerNorm được tính như sau ( và là hai tham số học được):
Kết hợp lại với nhau:
Xét vector input có chiều là khi đó:
- Attention Component:
- Feedforward Component:
6. Song song hoá Transformers
Thay vì đưa từng token có chiều là , ta đưa input là cả ma trận input gồm token và có chiều là . Các LLM thường có từ 1000 đến 32000, có những LLM có thể handle cao hơn như 128k hay 1M (Gemini) bằng kỹ thuật nâng cao hơn
Song song hoá Attention:
là ma trận với dòng là các query vector và có size là , tương tự ma trận có dòng là các key vector, có dòng là các value vector, với size tương ứng là và .
Khi đó để tính tích trong của từng query và key vector ta chỉ cần tính .
Sau khi đã có ta chỉ cần scale ma trận (scale từng phần tử ma trận) và tính softmax cho từng dòng trong ma trận:
Thế nhưng điều đặc biệt là ta có thêm hàm , có thể thấy phép nhân ma trận tính luôn tích vô hướng giữa một query hiện tại với các key phía sau nó và điều này đi ngược lại ý tưởng của Transformer khi tính attention dựa trên query và các key (hay từ) đứng trước nó. Vì vậy ta sẽ thực hiện mask những phần tử “phía sau” này đi.
Ta có thể dùng mask thông qua một ma trận tam giác trên với (khi ta để , softmax sẽ tự đưa các giá trị ấy về ). Do việc “mask” này, ta còn gọi nó là Masked Self Attention hay Causal Attention.

Hình như vẫn còn thiếu lớp Embedding và Unembedding nhỉ, thật ra những lớp này rất quan trọng nhưng mình sẽ để các bạn tự tìm hiểu, thật ra mình cũng viết hết nổi rồi hẹ hẹ.
7. Tài liệu tham khảo
- Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models, Daniel Jurafsky and James H. Martin2025https://web.stanford.edu/~jurafsky/slp3/
- Mechanistic Interpretability for AI Safety -- A Review, Leonard Bereska and Efstratios Gavves2024https://arxiv.org/abs/2404.14082
- Distributed representations, simple recurrent networks, and grammatical structure, Elman, Jeffrey L.Machine Learning, 1991https://doi.org/10.1007/BF00114844
- Effective Approaches to Attention-based Neural Machine Translation, Minh-Thang Luong and Hieu Pham and Christopher D. Manning2015https://arxiv.org/abs/1508.04025
- Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau and Kyunghyun Cho and Yoshua Bengio2016https://arxiv.org/abs/1409.0473
- Attention Is All You Need, Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin2023https://arxiv.org/abs/1706.03762
- Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey, Yunpeng Huang and Jingwei Xu and Junyu Lai and Zixu Jiang and Taolue Chen and Zenan Li and Yuan Yao and Xiaoxing Ma and Lijuan Yang and Hao Chen and Shupeng Li and Penghao Zhao2024https://arxiv.org/abs/2311.12351